Introduction: Why Modern Systems need Kafka
- Reduced throughput
- Performance bottlenecks
- Increased system complexity
Furthermore, connecting several systems with each other in traditional ways can be cumbersome and highly dependent.
To address these challenges, Apache Kafka was introduced by LinkedIn in 2011 as a distributed, high-performance messaging and streaming platform. Later, it became open source under the Apache Software Foundation.
Sounds interesting?
In this blog post, you will learn about:
- What Kafka is and how it works
- Why it is so fast
- Real-world use cases
- A practical Kafka + .NET implementation
What is Apache Kafka?
Apache Kafka is a technology that helps applications to send, store, and process data continuously in real time. It is well designed to handle large amounts of data while staying fast, scalable, and reliable.
It operates on publish-subscribe model:
- Producers publish data to topics
- Consumers subscribe and consume that data
Kafka is widely used in:
- Logging
- Streaming data
- Real-time analytics
To ensure durability, Kafka replicates data across multiple brokers, making it highly resilient.
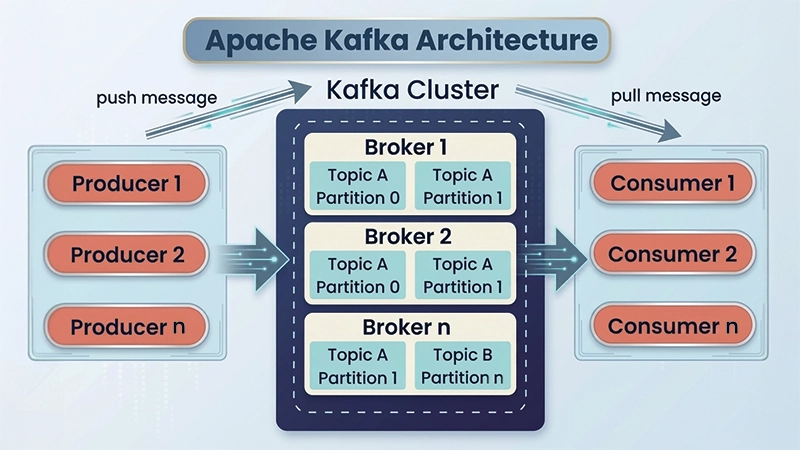
What Makes Kafka So Fast?
Kafka’s exceptional performance is driven by a combination of smart design principles:
1. Sequential I/O
Kafka uses a log-based storage mechanism, writing data sequentially to disk
Benefits:
- Faster disk operations
- Reduced latency
- Near RAM-level performance
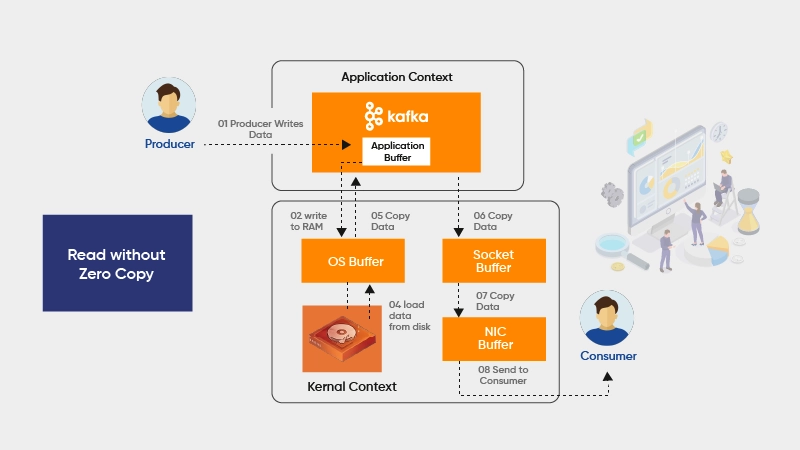
2. Zero Copy Principle
Kafka minimizes data copying between application and kernel space.
Benefits:
- Faster data transfer
- Lower CPU overhead
3. Message Compression & Batching
Kafka compresses and batches messages before sending.
Benefits:
- Reduced network usage
- Higher throughput
Why Kafka is Fast?
Why Choose Kafka?
Apache Kafka is widely adopted due to the following advantages:
1. High Performance
2. Durability (Non-volatile Storage)
Messages get stored in a persistent way and can be accessed at any time.
3. Distributed Architecture
4. Decoupled Communication
Producers and consumers are independent
5. Fault Tolerance
Data is replicated across multiple nodes
6. Scalability
Processing more messages while maintaining performance
Use Cases of Apache Kafka
1. Data Streaming
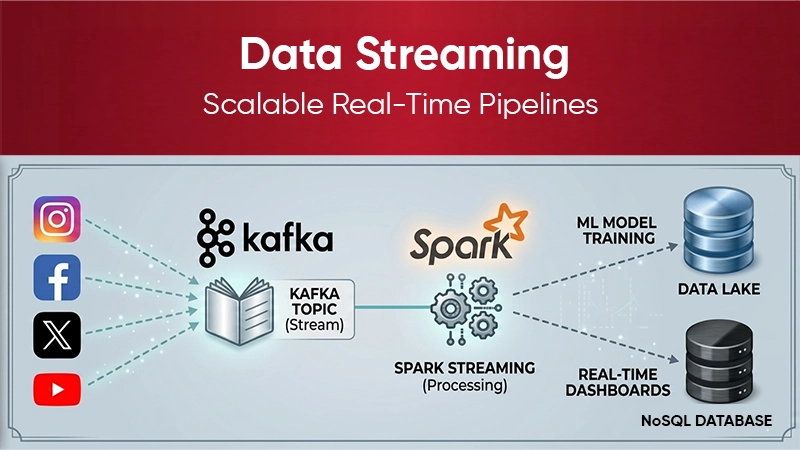
Kafka enables real-time data processing using tools like:
– Kafka Streams
– Apache Spark
– Apache Flink
2. Log Aggregation
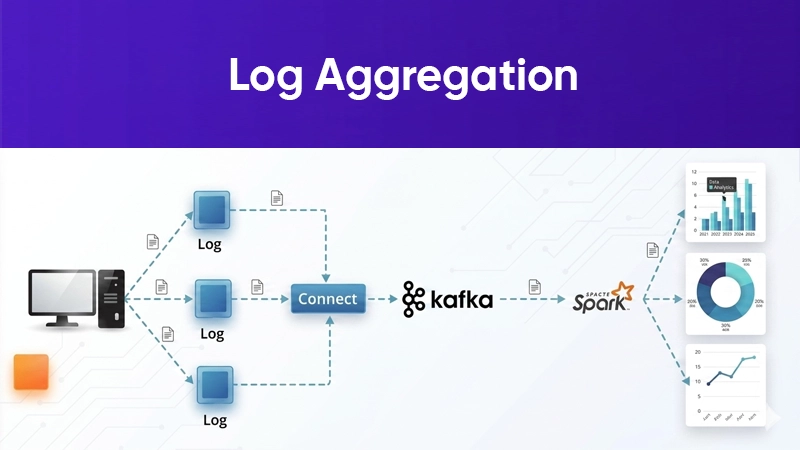
Centralizes logs from multiple systems for easier monitoring and debugging.
3. Data Replication
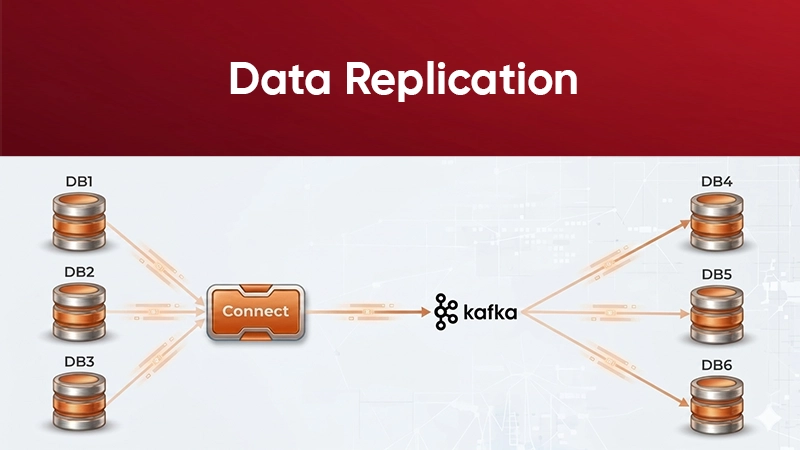
Keeps data consistent and available in multiple systems or data centers
4. Messaging Queue
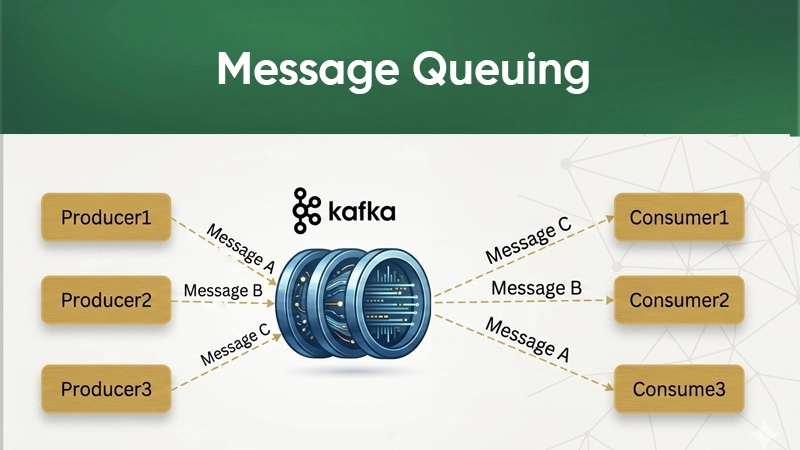
Acts as a high-performance messaging system for microservices communication.
5. Web Activity Tracking
Tracks user behaviour such as clicks, page visits, and interactions in real time.
Hands on kafka + .NET Implementation
Let us get started with understanding Kafka with practical example. For that purpose. I have created two applications here:
– Producer (Sender)
– Consumer (Receiver)
👉 The Producer sends messages to Kafka, and the Consumer reads them.
Step 1: Install Kafka
Kafka can be run on either of below ways:
– Local setup OR
– Docker (recommended for easy setup)
Step 2: Add Required Package
In your .NET project, install:
dotnet add package Confluent.Kafka
Step 3: Producer (Send Message)
var config = new ProducerConfig
{
BootstrapServers = "localhost:9092"
};
using var producer = new ProducerBuilder<Null, string>(config).Build();
await producer.ProduceAsync("orders", new Message<Null, string>
{
Value = "Order Created"
});
Console.WriteLine("Message sent successfully!");
👉 What this does:
– Connects to Kafka
– Sends message to orders topic
Step 4: Consumer (Read Message)
using Confluent.Kafka;
var config = new ConsumerConfig
{
BootstrapServers = "localhost:9092", GroupId = "order-group",
AutoOffsetReset = AutoOffsetReset.Earliest
};
using var consumer = new ConsumerBuilder<Ignore, string>(config).Build(); consumer.Subscribe("orders");
while (true)
{
var result = consumer.Consume(); Console.WriteLine($"Received: {result.Message.Value}");
}
👉 What this does:
– Subscribes to orders topic
– Continuously reads message
Use Kafka when:
You need high performance
Kafka can process millions of messages per second without affecting its perfomance
Your system needs to scale easily
You can add more brokers instead of redesigning the system
You want fault-tolerant systems
Data is replicated, so no data loss even if a server fails
You are building microservices
Kafka helps decouple services (no direct dependency)
You need data replay capability
You can reprocess old messages anytime
You require real-time processing
Useful for dashboards, notifications, and live tracking
Avoid Kafka when
Your project is small or simple
Kafka might be too complicated for basic use cases
You want easy setup and fast development
Kafka setup requires some knowledge of brokers, topics, partitions
You need strict message ordering everywhere
Kafka guarantees order of messages only within a topic partition
You cannot handle duplicate messages
Kafka may deliver messages more than once or at-least-once delivery.







