
The strangler fig pattern is about incrementally migrating from a legacy system to a modern one. We gradually replace the functional blocks of a system with new blocks, strangle the older system’s functionalities one by one, and eventually replace everything with a new system. Once the older system is entirely strangled, it can be decommissioned.
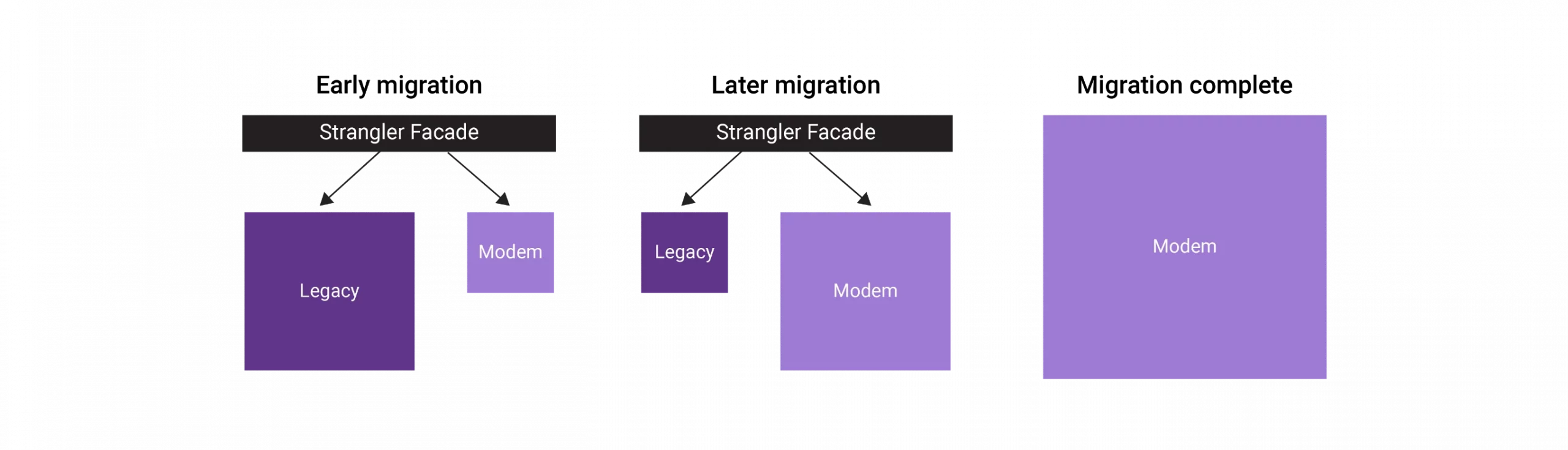
You can use this pattern when gradually migrating from a back-end application to a new architecture. The strangler fig pattern may not be suitable if the requests to the back-end system cannot be intercepted. When dealing with smaller systems without much complexity, it’s better to go for a wholesale replacement rather than choosing this pattern.
Here’s how you can implement the strangler fig pattern:

Transform
Given below is an example of legacy code and architecture, where all the modules are tightly coupled, and it is hard to maintain them in the same condition with upcoming modern technology.
Here, the loan service contains three services: personal, partner, and business loans.
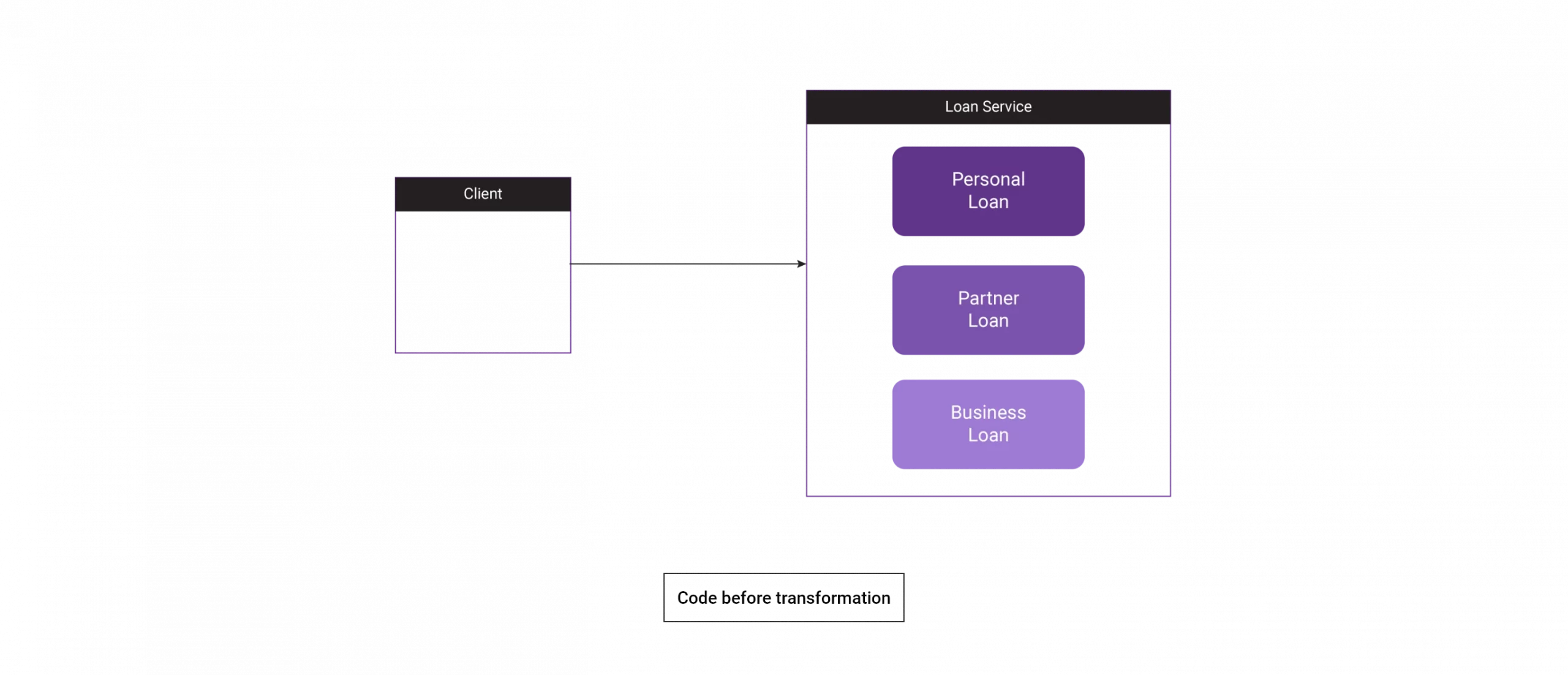
Code Snippet:

We choose the personal loan method as the first to refactor. It could be unreliable, inefficient, outdated, or even hard to get skilled developers to maintain the same legacy code.
Let’s make a new implementation for the personal loan service and divide it into separate classes or even a microservice. After correcting or refactoring our code snippet, we can create a Proxy class for handling both new and old approaches.
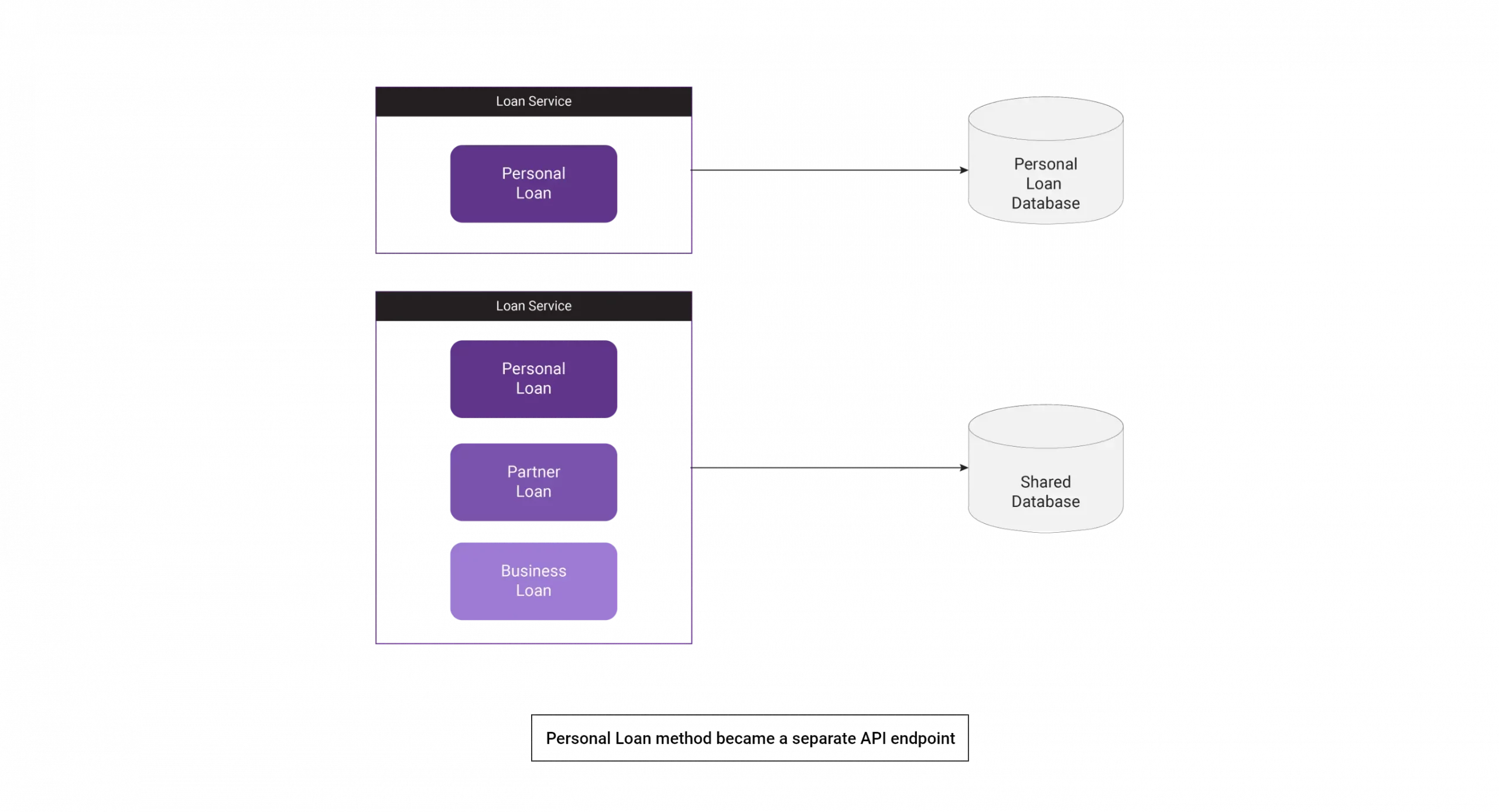
We have developed a new API with a separate database. Initially, all services used a shared database, but as part of code refactoring, the personal loan module had to be decoupled from the existing database. The same applies to the API endpoint.
Coexist: where two implementations coexist together.
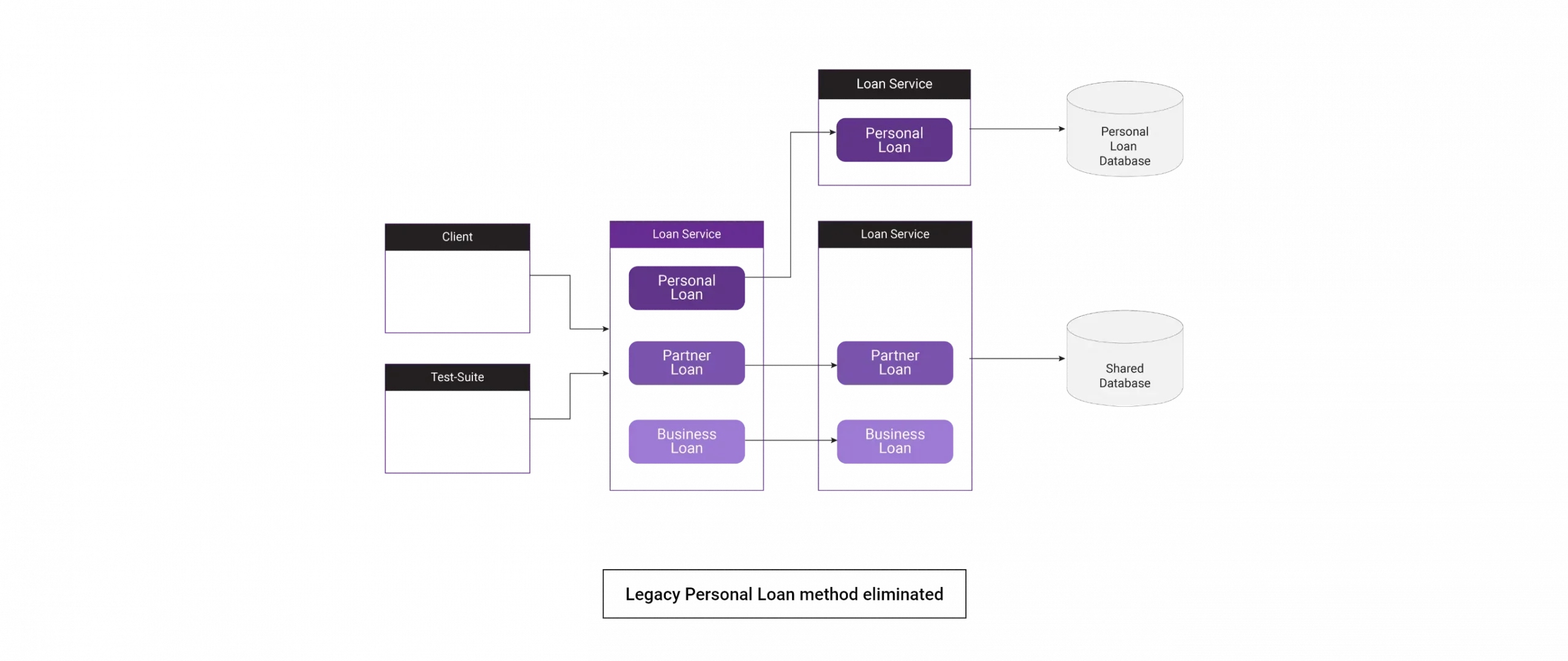
Here we have extracted another layer abstraction from the loan service and made it coexist with the original service. Both services provide the same functionality, and the signature of the services is also the same. The proxy will decide whether the call goes to a new API or an existing service.
Run new service with a fallback of old service: In such a scenario, we always have a safety buffer if the new one fails.
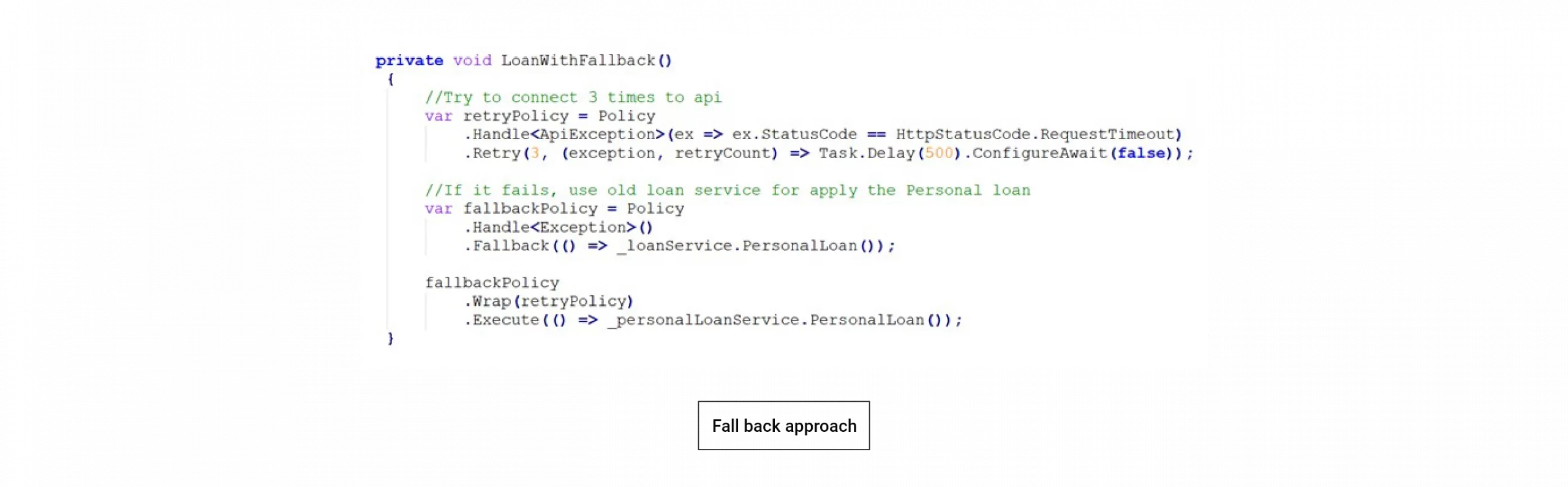
Run both services and compare the output to confirm whether the new one works fine. In such a scenario, to avoid duplicate loans or transactions, we should turn off all external references and assume that we accept loan data only from one source.
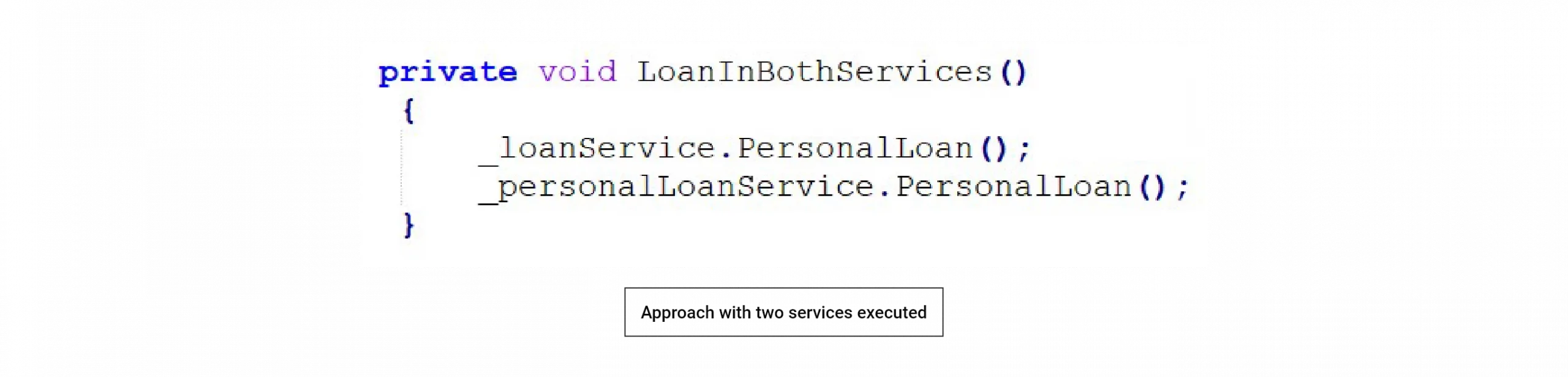
Use a feature flag to decide whether to use the new API or the old one. Here in the configuration, we can set a flag, and it will choose how the call will work — whether with legacy API or with Newly developed service.
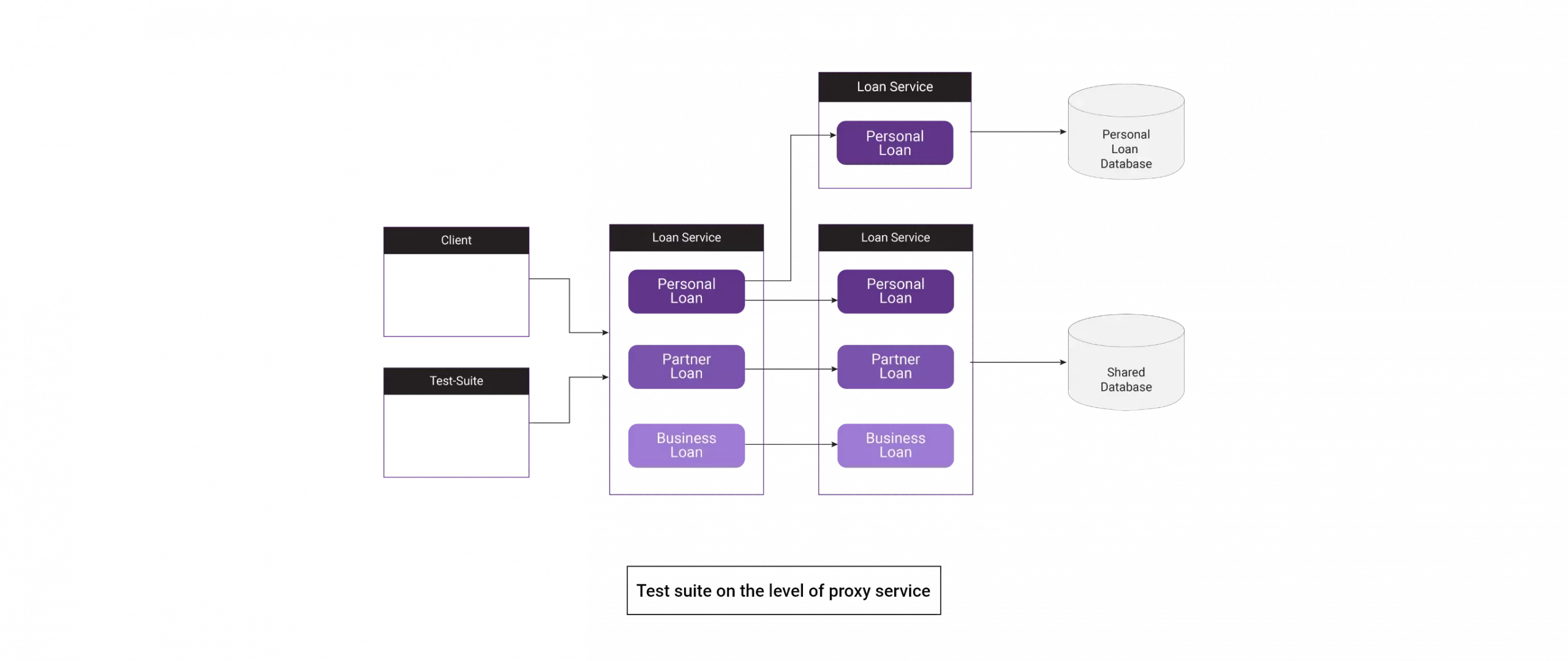
While refactoring, we might miss some tests, or the existing tests might be heavy to maintain. The proxy service created helps us ensure that the implementation completely covers the old one.
Let’s implement integration or even e2e tests, where we test observable behaviors instead of implementation details. Remember that anything we refactor or change should have a certain level of test coverage. The better the coverage, the more confidence we get in how the code works. If the refactoring code does not contain enough tests, we should start by covering it and writing test cases for all features, behaviors, and edge cases.
We should start testing the Proxy class if unit tests cannot cover the code. Sometimes e2e tests might be the only way to cover both implementations.
Once we catch up and mitigate all the problems in the new approach, we can eliminate the legacy code. Hereafter, the personal loan module directly approaches the new API.













Recent Comments